JOURNAL OF INFORMATION SCIENCE THEORY AND PRACTICE
- P-ISSN : 2287-9099
- E-ISSN : 2287-4577
- Publisher : 한국과학기술정보연구원
- CCL :


6개 논문이 있습니다.

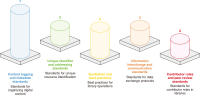
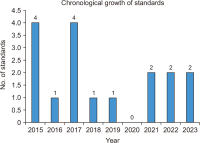
This paper provides a systematic review of American National Standards Institute-National Information Standards Organization (ANSI-NISO) standards that have been published or revised since 2015, and the aim of the paper is to review them in terms of thematic orientation, developmental patterns, and future implications to the digital library systems presently in use. In this study, 17 standards were grouped into five broad thematic clusters: content tagging and metadata standards, unique identifiers and addressing systems, guidelines and best practices, information interchange and communication standards, and contributor roles and peer-review terminology. The findings indicate a significant move toward extensible markup language based content structuring (especially journal article tag suite and standards tag suite), increased metadata interoperability, resource synchronization system, and transparency based academic communication standards like contributor roles taxonomy and standardized peer-review language. Together, these standards enhance fundamental digital library capabilities through enhanced metadata quality, the means to discover and exchange resources seamlessly, long-term digital preservation, and machineactionable and interoperable workflows in the spirit of open science. The analysis also identifies that despite the adoption of individual standards, they are seldom studied as a structure to sustain digital library ecosystems. The results highlight the importance of integrating standards that facilitate the deployment of new technologies like linked data, artificial intelligence, and data-driven digital scholarship, and thus assist in making ANSI-NISO standards key to building sustainable and future-oriented digital library systems.
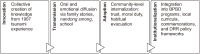
This study examines smong, an indigenous oral tradition from Simeulue Island, Indonesia, as a model of community-driven disaster communication. Drawing on Rogers’ Diffusion of Innovation (DOI) theory, it investigates how smong originates from the collective memory of the 1907 tsunami. It functions as a non-technological social innovation transmitted across generations through storytelling, rituals, education, and digital media. Using qualitative communication ethnography, data were collected through interviews, participant observation, and document analysis involving 35 participants across four subdistricts. NVivo-based thematic analysis identified six coding categories, including innovation stages, communication channels, and actor roles. Findings reveal that smong diffusion follows a four stage process: innovation, transmission, adoption, and institutionalization. Kinship networks, emotional trust, and cultural performances sustain knowledge continuity. Unlike top-down early warning systems, smong demonstrates a bottom-up diffusion ecology that transforms trauma into resilience through moral communication and shared memory. The study extends DOI theory by situating it within oral cultural innovation, emphasizing that innovation may emerge from lived experience and social trust rather than technology. The proposed smong diffusion model offers both theoretical and policy implications for integrating indigenous knowledge into community-based disaster risk reduction.
This scoping review maps existing literature on how librarians in developing countries apply evidence-based information practice (EBIP), identifying key themes and evidence gaps for future research. The review followed Arksey and O’Malley’s five-stage framework and applied the Preferred Reporting Items for Systematic Reviews and Meta-Analyses 2020 checklist alongside the Critical Appraisal Skills Programme for appraising study quality. From 6,693 records retrieved, ten studies met the inclusion criteria. The mapped studies suggest that librarians apply EBIP in diverse professional activities such as collection development, advocacy, reference services, information literacy instruction, decision-making, evaluation, monitoring performance, and enhancing service quality. Evidence-based approaches were considered to improve decision-making and user engagement. Barriers identified include limited research awareness, insufficient training, restricted access to quality evidence, inadequate information and communication technology infrastructure, and digital inequalities. The findings indicate that librarians could benefit from integrating EBIP into library and information science curricula by providing a structured implementation roadmap, while encouraging policymakers to prioritize evidence-based approaches in the library sector. Practical strategies identified include investment in capacity building, fostering partnerships, strengthening user feedback mechanisms, and adopting affordable digital tools. The studies reviewed identified the importance of embedding EBIP into daily library practices in developing countries to ensure relevant, responsive, and impactful information services. Evidence gaps identified for further research include digital skill levels and EBIP adoption, user engagement and influence on EBIP practices, EBIP framework and workflow for developing countries, and institutional barriers to implementation of EBIP.
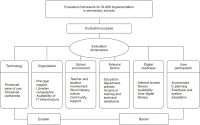
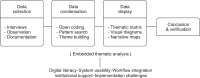
Senayan Library Management System (SLiMS) is an open-source library automation platform adopted in over 24 countries to enhance operational efficiency and service quality. Despite its growing global usage, there is a lack of empirical research examining the implementation of this approach in elementary schools, particularly in developing countries. This study investigates the barriers and enabling conditions influencing the adoption of SLiMS in Indonesian elementary school libraries. Using a qualitative case study approach, data were collected through in-depth interviews with librarians from selected elementary schools implementing SLiMS. Thematic analysis was employed to examine the socio-technical dynamics influencing system adoption. The findings reveal three main challenges: limited human resource capacity, organisational inertia, and inadequate technological infrastructure. On the other hand, organisational readiness and the digital competencies of staff serve as key enablers for successful implementation. The findings suggest that SLiMS can facilitate a more inclusive digital transition for resourceconstrained libraries by addressing the gap between advanced automation and basic school requirements. This suggests that system developers should prioritize modular, low-bandwidth features to support the long-term viability of digital libraries in rural educational settings.
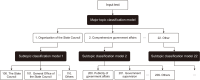
As the demand for cross-national policy comparisons intensifies, automating the classification of vast volumes of policy texts through deep learning presents a viable solution to alleviate manual labor and enhance policy matching efficiency. This study proposes an automated multi-topic policy classification system grounded in the policy perceptron framework, augmented by the RoBERTa-whole word masking model pretrained on domain-specific corpora. The study curated a dataset of policy documents, applied the model for multi-label classification, and rigorously evaluated its performance via comparative experiments against baseline models. The results present performance for our model in multi-topic scenarios, with robustness to imbalanced classes and lengthy texts. Furthermore, the authors benchmarked the approach against general-purpose large language models, revealing that this domain-tailored model achieves higher classification efficacy. These findings highlight the advantages of specialized deep learning architectures for policy text analysis, examining the conceptual and methodological implications of automating policy classification and offering practical insights for scalable policy organization and future research in automated governance tools.

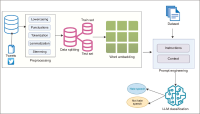
Hate speech ought to be identified and minimized to diminish the undesirable influx of toxic content on the Internet, particularly in the fields of sensitive matters, such as the climate change debate. This article analyzes hate speech detection using climate change-related information and focuses on tweet classification and the identification of the hate target via prompt engineering with large language models (LLMs). Specifically, we compare three instruction-tuned LLMs, TinyLlama, Flan-T5, and Gemma, and evaluate them in contrast to a standard transformer baseline, bidirectional encoder representations from transformers (BERT). The aspects of the experimental framework include prompt design in a systematic way, reproducible implementation environments, and performance measures such as accuracy, precision, recall, and F1-score. The results suggest that prompt-based LLMs for zero-shot inference of hate speech do not require task-specific training. However, the finetuning BERT baseline is more precise and achieves a high F1-score, suggesting the importance of classification reliability. The findings indicate the pros and cons of prompt engineering, which is feasible but highlights the need for prompt design and model choice to achieve reliable hate speech detectors in climate-related speech.